Many properties of graphs are at least partially determined by the degree sequence of the graph. As we saw in our discussion of centrality, for example, the centrality of a node is highly-correlated to its degree. As we’ll see later in these notes, the degree sequence also plays a major role in determining whether, for example, an epidemic can spread on a network. On the other hand, not all properties of graphs are so constrained by the degree sequence. For example, when we studied the structure of empirical networks, we saw that the density of triangles (as measured by the transitivity) varies strongly between real-world networks and their degree-preserving random counterparts.
So, which properties of a graph are controlled by the degree sequence? One way to approach this problem is to study models of random graphs in which the degree sequence is held constant, either exactly or approximately. In this set of notes, we’ll introduce several such models and develop some of their properties.
Fixing a Degree Sequence: The Configuration Model
In the configuration model, we choose a degree sequence. We then attempt to generate a random graph that has exactly that degree sequence.
Definition 8.1 (Configuration Model) Consider a graph with \(n\) nodes. Let \({\bf k} \in \mathbb{N}^n\) be the degree sequence, where \(k_i\) is the degree of node \(i\).
A configuration model is a uniform distribution over graphs with degree sequence \({\bf k}.\)
It’s not guaranteed that it is always possible to generate a graph with degree sequence \(\mathbf{k}\).
Exercise
Give a necessary condition on \(\sum_{i = 1}^n k_i\) for it to be possible to form a graph with degree sequence \(\mathbf{k}\).
In fact, it is possible to give a complete characterization of the degree sequences \(\mathbf{k}\) which can be realized as simple undirected graphs; this characterization is given by the Erdős-Gallai theorem(Erdös and Gallai 1960).
Sampling From Configuration Models
It’s surprisingly complicated to draw a sample from a configuration model random graph. We can draw approximate samples from the configuration model using the stub-matching algorithm.
In stub-matching, we create a list of “stubs,” or half-edges. Each node \(i\) with degree \(k_i\) appears in this list \(k_i\) times. We form edges by picking two stubs at a time out of the list and forming an edge between them. Let’s implement this stub-matching algorithm. Before we do, we’ll load in our favorite example graph and extract its degree sequence.
Show code
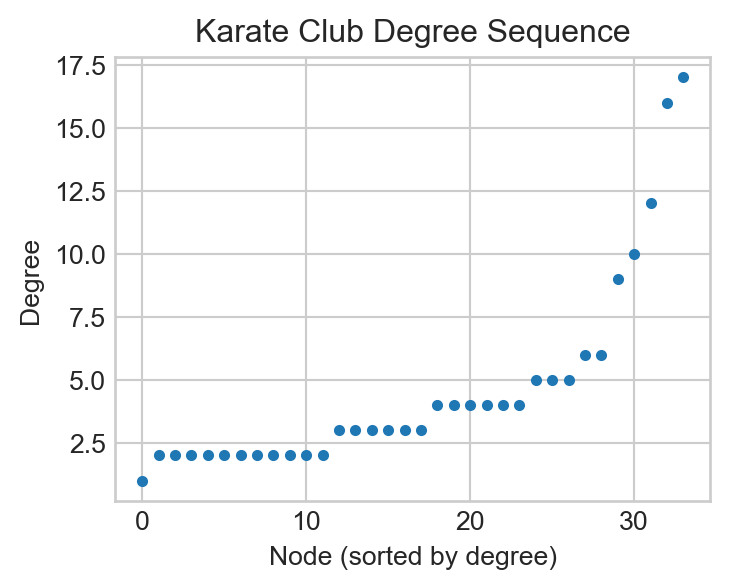
import networkx as nximport numpy as npfrom matplotlib import pyplot as pltplt.style.use('seaborn-v0_8-whitegrid')plot_kwargs = {"node_size" : 100, "edgecolors" : 'white', "node_color" : "steelblue", "width" : 0.5, "edge_color" : "darkgrey"}G_Karate = nx.karate_club_graph()deg_seq = [k for n, k in G_Karate.degree()]fig, ax = plt.subplots(1, 1, figsize = (4, 3))ax.scatter(np.arange(0, len(deg_seq)), np.sort(deg_seq), s =10)labs = ax.set(xlabel ="Node (sorted by degree)", ylabel ="Degree", title ="Karate Club Degree Sequence")
Figure 8.1: Sorted degree sequence of the karate club graph.
Now we’ll implement an algorithm to perform stub-matching. First, we create the list of stubs. Each node appears a number of times equal to its degree.
Now we need to take random pairs from this list of stubs. We could do this with a loop, but another way is to shuffle the list and then reshape it into a list of pairs:
Now we can create a graph from our newly-constructed edge-list. Importantly, this graph might contain both self-loops and multi-edges, and so we need to use the nx.MultiGraph constructor.
G = nx.MultiGraph()edges = G.add_edges_from(edge_list)
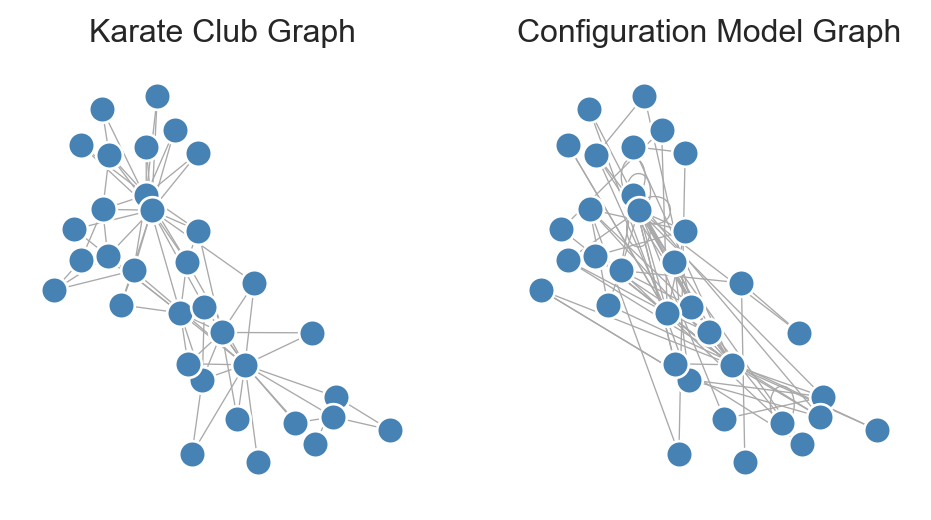
Here’s how our random graph compares to our original:
Figure 8.2: Original karate club graph alongside a random graph formed via stub-matching. The random graph has the same degree sequence, but also self-loops and multi-edges.
The stub-matching algorithm can produce multiedges and self-loops, which can cause the graph to not be simple. However, Bollobás (1980) proved that, when the graph is sparse, the expected number of multi-edges and self-loops does not grow with network size. One can, as a result, show these structures are rare, and can often be ignored in arguments. In practical terms, we often discard the self-loops and multi-edges when constructing the graph; this results in the degree sequence no longer being exactly preserved, but the effect is u sually small.
Fosdick et al. (2018) discuss the subtleties that arise due to whether we allow or disallow multiedges and self-loops and whether we choose to label stubs distinctly (as opposed to only labeling vertices). These choices result in different spaces of graphs from which we are sampling. If we want to sample a simple graph from a configuration model with exactly the specified degree sequence, stub-matching is no longer sufficient. Instead, we need to rely on edge-rewiring algorithms, which randomly swap edges between nodes of the graph to randomize the graph while ensuring that the degrees of nodes remain constant. NetworkX implements a version of such an algorithm. The user needs to specify how many rewiring steps should be performed.
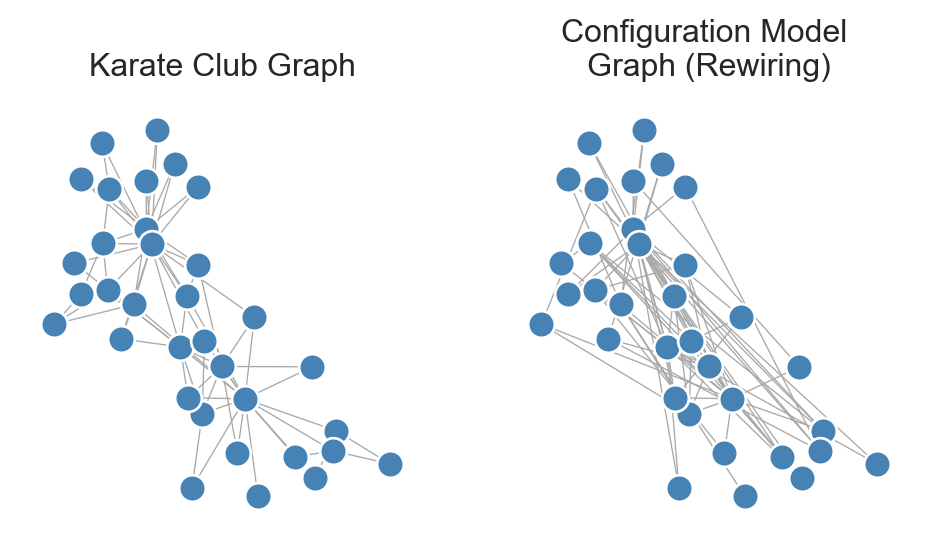
G = nx.random_reference(G_Karate, connectivity =False, niter =1000)
Figure 8.3: Karate club graph alongside a random graph formed by many successive rewirings. The random graph has the same degree sequence as the karate club graph and is simple, but is not guaranteed to be a uniform sample from the set of all such graphs.
This algorithm is guaranteed not to produce multiedges or self-loops and therefore exactly preserves the degree sequence. However, it can be much slower to generate random graphs this way, and it is difficult to know how many iterations are necessary to ensure that the resulting graph is “random enough.”
Technically, the rewiring process creates a Markov chain on the space of graphs, and the question of whether the graph is “random enough” is a question about the mixing time of the Markov chain.
Expected Degree Sequences: The Chung–Lu Model
Some of the challenges with stub-matching arise from the requirement that we generate a graph with a specified degree sequence \({\bf k}.\)Chung and Lu (2002) relax this constraint and generate networks whose degree sequences are approximately\({\bf k}\)in expectation, which avoids some of these issues.
Suppose that we want to generate a graph with \(n\) nodes where the degree of node \(i\) is approximately equal to \(k_i\). We’ll again think with stubs: if node \(i\) has degree \(k_i\), then it has \(k_i\) stubs. There are a total of \(2m\) stubs, of which \(k_i\) are already attached to \(i\), so the number of stubs \(i\) could attach to is \(2m-k_i\). Of these, \(k_j\) are attached to node \(j\). So, the probability that a given stub of \(i\) connects to node \(j\) is approximately \(k_j/(2m-k_i)\), and there are \(k_i\) such stubs: \[
\mathbb{P}(\text{node $i$ stub connects to node $j$}) = \frac{k_j}{2m-1} \approx \frac{k_j}{2m}
\]
for large \(m\). Summing over all \(k_i\) stubs, we have
\[
\begin{aligned}
\mathbb{E}[\text{number of edges between $i$ and $j$}] &\approx \frac{k_ik_j}{2m} \,.
\end{aligned}
\]
So, we can place down a Poisson-distributed number of edges between \(i\) and \(j\) with mean \(k_ik_j/2m\). When \(k_ik_j \ll 2m\), this is very similar to placing down a single edge with probability \(k_ik_j/2m\); the probability of placing down two or more edges becomes very small.
We might notice that this feels a little similar to the \(G(n,p)\) model, and in fact, this is by construction. The degree of node \(i\) will be Poisson distributed with mean \(k_i\) under the assumptions given above. This means that, instead of stub-matching, we can use an algorithm like for a \(G(n,p)\) network by placing an edge between two nodes with probability \(P_{ij} = \frac{k_ik_j}{2m}\).
Another assumption required here is that the maximum degree is not too large in comparison to \(n\).
Exercise
Implement a function chung_lu(deg_seq) that generates a graph with expected degree sequence approximately equal to the input deg_seq in expectation using the algorithm described above. Your algorithm should return a networkx graph object. You can choose to either place a Poisson-distributed number of edges between each pair of nodes with the appropriate mean or simply place a single edge with the appropriate probability.
Hint: You can use itertools.combinations(range(n), 2) to loop through all pairs of nodes in a graph.
NetworkX supplies a built-in Chung-Lu implementation:
G = nx.expected_degree_graph(deg_seq, selfloops=False)
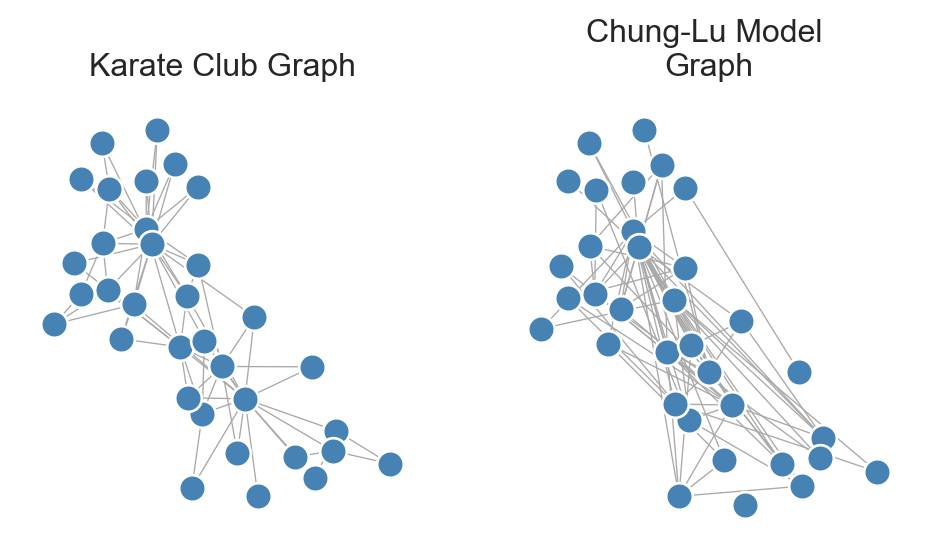
Visually, this looks fairly similar to the configuration model and quite different from the original graph:
Figure 8.4: Karate club graph alongside a Chung-Lu random graph.
We can compare the degree sequence of the random graph we constructed to that of the original graph:
Show code
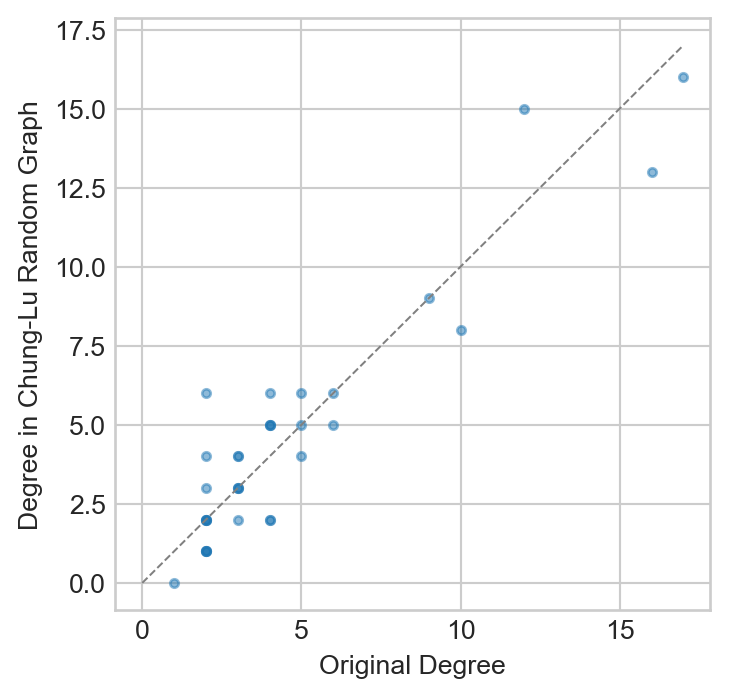
chung_lu_deg_seq = [k for n, k in G.degree()]fig, ax = plt.subplots(1, 1, figsize = (4, 4))plt.plot([0, 17], [0, 17], color ="grey", linestyle ="--", linewidth =0.75)ax.scatter(deg_seq, chung_lu_deg_seq, s =10, label ="Karate Club", alpha =0.5)t = ax.set(xlabel ="Original Degree", ylabel ="Degree in Chung-Lu Random Graph")
Figure 8.5: Comparison of the degree sequences of the karate club graph and a Chung-Lu random version. The line of equality, corresponding to nodes which have the same degree in both graphs, is shown.
We observe that the degrees in the Chung-Lu model are correlated with but not exactly equal to the original degrees. We notice that the nodes with high degrees in the original graph tend to have lower degree in the Chung-Lu model; this is expected as shown in the following exercise.
Exercise
Show that the expected degree \(\mathbb{E}[K_i]\) of node \(i\) in the Chung-Lu model is equal to \(k_i - \frac{k_i^2}{2m}\).
Fixed Degree Distributions
When making mathematical arguments, you may want to consider a “general graph with degree distribution \(p_k\).” That is, we’re interested in a graph in which proportion \(p_k\) of all nodes have degree \(k\). This is a more flexible approach than specifying the degree \(k_i\) of each individual node in a graph via the degree sequence \(\mathbf{k}_i\).
We can do this using a slight modification to the strategy described above.
Draw a degree sequence \(\{k_i\}\) from the given distribution \(p_k.\)
In practice, this is most likely achieved by \(n\) independent draws from \(p_k\). A particular degree sequence then appears with probability \(\Pi_i p_{k_i}.\)
Construct a graph with this degree sequence either exactly (configuration model) or approximately and in expectation (Chung-Lu) as described above.
Once again, we can easily run into some challenges here. With the algorithm described above it is very possible to generate a degree sequence with an odd number of stubs, and such degree sequences would need to be discarded. The concerns about self-edges, multiedges, and labeling that apply to the configuration model and Chung-Lu models still apply here.
Exercise
Write a function degree_dist_random_graph(n, p) which accepts a number of nodes n and a desired degree distribution p, which can be passed as a numpy array. Your function should (a) sample a degree sequence of length n from the desired degree distribution p and then (b) construct a graph with approximately this degree sequence using the Chung-Lu model.
We assume that p is a valid probability vector: its entries are nonnegative and sum to 1. p[0] is assumed to be the proportion of nodes of degree 0, p[1] the proportion of nodes of degree 1, and so on. Passing p = np.array([0, 0, 0, 0]), for example, would result in a regular graph where all nodes have degree 3.
Hint: np.random.choice(np.arange(len(p)), n, p = p) will sample n random integers from 0, 1, ..., len(p) - 1 with probabilities given by p.
Once you’ve completed your implementation, generate some graphs with numbers of nodes ranging from 10 to 1000. Compare the degree distribution of the generated graphs to the desired degree distribution. You can plot the full distributions, check the means and variances, or any other comparison method you find interesting.
While the two models we describe here are different, we expect them to behave similarly in the large-\(n\) limit, where a sequence drawn from a degree distribution more accurately captures the underlying distribution. This approximation is justifiable using formal asymptotic reasoning when \(n\) grows large and the degree distribution \(p_k\) has variance that doesn’t grow too rapidly with \(n\).
There are some important special cases that we’ve already encountered:
Using a Poisson degree distribution approximately recovers the \(G(n,p)\) model, excepting that we are able to generate self- and multiedges with this configuration model variant.
Using a power-law degree distribution helps us mathematically study the properties of scale-free networks, like those generated by preferential attachment.
With this approximation scheme, we can go on to study one of the most important properties of random graphs: the excess degree distribution.
Excess Degree Distribution
Consider a configuration model with degree distribution \(p_k\) (so a fraction \(p_k\) of nodes have degree \(k\)). This means that \(p_k\) can be viewed as the probability that a node chosen uniformly at random from our network has degree \(k\). We’ll let \(n_k = np_k\) be the expected number of nodes of degree \(k\).
Now, suppose we choose a node uniformly at random and follow an edges to this node’s neighbor (if it has one). What is the probability that the neighbor will have degree \(k\)?
Exercise
Explain why the probability that the neighbor has degree \(k\) is not also \(p_k\).
We’ll again reason using stubs. First, let’s calculate the probability that we have a stub connected to a particular degree \(k\) node. A node with degree \(k\) has \(k\) stubs, and there are \(2m-1\) possible stubs other than the one we selected. So,
Thus, because in expectation there are \(np_k\) nodes of degree \(k\), we have
\[
\begin{align}
\mathbb{P}(\text{edge ends at any degree $k$ node}) = \frac{k}{2m-1}n p_k \approx \frac{k}{2m}np_k \,.
\end{align}
\]
Let \(\langle k \rangle = \frac{1}{n} \sum_{i = 1}^n\) be the mean degree. Then, we must have that \(\langle k \rangle = \frac{2m}{n}\), so the probability that we reach a node of degree \(k\) is approximately \(\frac{1}{\langle k \rangle}k p_k.\) In other words, this probability is proportional to \(kp_k\) (not \(p_k\) as we might expect). This quantity is called the edge-biased degree distribution.
We can calculate the additional number of edges attached to a neighbor other than the edge we arrived along. For a node to have \(k\) additional neighbors, it must have degree \(k+1\). So, the probability that a neighbor has degree \(k+1\) is \[
\begin{align}
q_k = \frac{(k+1)p_{k+1}}{\langle k \rangle} \,.
\end{align}
\]
This quantity is called the excess degree distribution.
The Friendship Paradox
Suppose we model a social network of friends with degree-preserving random graph. How many friends does your friend have?
To see this, let’s calculate the average degree of a neighbor of a randomly chosen node using the edge-biased degree distribution.
\[
\begin{align}
\sum_k k \frac{1}{\langle k \rangle}kp_k = \frac{1}{\langle k \rangle}\sum_k k^2 p_k\,.
\end{align}
\]
Let \(n\) be the total number of nodes and \(n_k\) be the number of nodes of degree \(k\).
Now we’ll simplify our expression with a reindexing trick. As written, we’ve indexed over node degrees \(k\), but we could choose to index over node labels \(i\) instead. Remembering that \(p_k = \frac{1}{n}n_k\), this gives: \[
\begin{align}
\frac{1}{\langle k \rangle}\sum_k k^2 \frac{1}{n}n_k = \frac{1}{\langle k \rangle n}\sum_i k_i^2 = \frac{\langle k^2 \rangle}{\langle k \rangle}\,,
\end{align}
\tag{8.1}\]
where \(\langle k^2 \rangle = \frac{1}{n} \sum_i k_i^2\). To get the first equality, we notice that the set \(\{n_1, (2)^2n_2, (3)^2n_3, \dots, (k_{max})^2 n_{k_{max}}\}\) has the same sum as \(\{k_1^2, k_2^2, ..., k_n^2\}\).
The quantity \(\langle k^2 \rangle\) is often called the second moment of the degree distribution. The first moment \(\langle k \rangle = \frac{1}{n}\sum_{i = 1}^n k_i\) is the mean degree.
Let’s compare this value to the expected degree of a randomly chosen node:
\[
\begin{aligned}
\frac{\langle k^2 \rangle}{\langle k \rangle} - \langle k \rangle = \frac{1}{\langle k \rangle}\left(\langle k^2 \rangle - \langle k \rangle^2\right) = \frac{\sigma_k^2}{\langle k \rangle}\,,
\end{aligned}
\tag{8.2}\]
where \(\sigma_k^2 = \langle k^2 \rangle - \langle k \rangle^2\) is the empirical variance of the degree distribution. As we know, the variance of a random variable is 0 if and only the random variable is constant. In the context of degrees, this corresponds to a \(k\)-regular graph. So, unless the graph is \(k\)-regular, \(\sigma_k^2 > 0.\) Thus,
\[
\begin{align}
\frac{\sigma_k^2}{\langle k \rangle} &> 0, \\
\Rightarrow \frac{\langle k^2 \rangle}{\langle k \rangle} - \langle k \rangle &> 0, \\
\Rightarrow \frac{\langle k^2 \rangle}{\langle k \rangle} &> \langle k \rangle \,.
\end{align}
\]
That is, the expected degree of a node’s neighbor (lefthand side) is greater than the expected node degree \(c\) … in other words, (in expectation), your friends have more friends than you do!
The intuition behind this idea is that a node with degree \(k\) appears as a neighbor to \(k\) other nodes, so high degree nodes are over-represented in the calculations.
The friendship paradox has some practical applications in network analysis and interventions. For example, to interrupt the spread of an illness with a limited number of vaccines, it’s useful to target high-degree nodes in social networks, as they are more likely to be infected and to infect others. But how to identify the high-degree nodes? The friendship paradox suggests a simple way: pick some people at random and ask them to recommend one of their friends. This is sometimes called acquaintance immunization and can be a relative effective strategy for vaccine distribution. See Rosenblatt et al. (2020) for some discussion of this and related strategies.
Let’s visualize the degree of each node in comparison to the average degree of its neighbors to get a feel for this result:
Show code
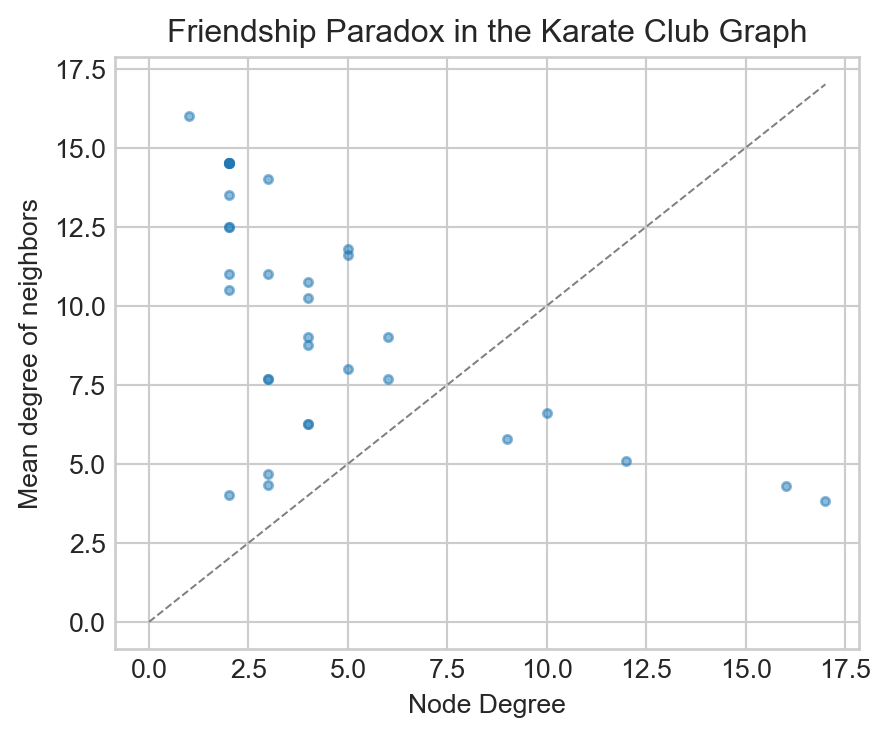
mean_degree = np.mean(deg_seq)neighbor_degrees =list(nx.average_neighbor_degree(G_Karate).values())fig, ax = plt.subplots(1, 1, figsize = (5, 4))ax.scatter(deg_seq, neighbor_degrees, s =10, alpha =0.5)ax.plot([0, 17], [0, 17], color ="grey", linestyle ="--", linewidth =0.75)t = ax.set(xlabel ="Node Degree", ylabel ="Mean degree of neighbors", title ="Friendship Paradox in the Karate Club Graph")
Figure 8.6: Computational illustration of the friendship paradox in the karate club graph. The average degree of the neighbors of a node tends to be higher than the degree of the node itself, with a few exceptions.
For most nodes (but not all), the mean degree of their neighbors is higher than their own degree. On average, the mean degree of a node in this graph is just half of the mean degree of that node’s neighbors.
We can verify Equation 8.1 by computing the appropriate quantities in two ways.
Exercise
Write a function which computes the average neighbor degree in the graph. Your function should loop through all nodes in the graph, collect the degrees of their neighbors, and combine those degrees in a large list (or similar data structure). You should then return the mean of that list.
Let’s compare our computational result to the result expected by theory.
Exercise
Implement the mathematical calculation of the average neighbor degree using Equation 8.1 and show that it agrees with your function in the previous exercise.
References
Bollobás, Béla. 1980. “A Probabilistic Proof of an Asymptotic Formula for the Number of Labelled Regular Graphs.”European Journal of Combinatorics 1 (4): 311–16.
Chung, Fan, and Linyuan Lu. 2002. “Connected Components in Random Graphs with Given Expected Degree Sequences.”Annals of Combinatorics 6 (2): 125–45.
Erdös, Paul, and Tibor Gallai. 1960. “Graphs with Given Degrees of Vertices.”Math. Lapok 11: 264–74.
Fosdick, Bailey K, Daniel B Larremore, Joel Nishimura, and Johan Ugander. 2018. “Configuring Random Graph Models with Fixed Degree Sequences.”Siam Review 60 (2): 315–55.
Rosenblatt, Samuel F, Jeffrey A Smith, G Robin Gauthier, and Laurent Hébert-Dufresne. 2020. “Immunization Strategies in Networks with Missing Data.”PLoS Computational Biology 16 (7): e1007897.