from matplotlib import pyplot as plt
import networkx as nx
import numpy as np
plt.style.use('seaborn-v0_8-whitegrid')
def unweight(G):
for source, target in G.edges():
G[source][target]['weight'] = 1
return G
G = unweight(nx.karate_club_graph())
A = nx.to_numpy_array(G)13 Spectral Clustering
Open the live notebook in Google Colab here.
$$
$$
We continue our study of the clustering problem. We’ll focus today on the problem of splitting a graph into two pieces. Suppose we have a graph \(G = (N,E)\) with adjacency matrix \(\mathbf{A}\in \mathbb{R}^n\). Our aim is to determine a vector \(\mathbf{z}\in \left\{0,1\right\}^n\) that splits the graph into two clusters: \(C_0 = \left\{i \in N : z_i = 0\right\}\) and \(C_1 = \left\{i \in N: z_i = 1\right\}\). We aim for these clusters to be “good” in some sense, which usually means that there are many edges within each \(C_i\) but relatively few edges between \(C_0\) and \(C_1\).
The problem of splitting a graph into two clusters is sometimes called the biclustering problem.
In this set of notes, we’ll introduce Laplacian spectral clustering, which we’ll usually just abbreviate to spectral clustering. Spectral clustering is an eigenvector-based method for determining such a vector \(\mathbf{z}\), or, equivalently, the two sets \(C_0\) and \(C_1\).
Defining the Spectral Clustering Objective
Many clustering algorithms proceed by optimizing or approximately optimizing a certain objective function.1 Spectral clustering is one such approximate optimization approach. In order to define the objective function for spectral clustering, we first need to introduce some notation.
1 Modularity maximization is an example we’ve seen before.
Definition 13.1 (Cut and Volume) The cut of a partition \((C_0, C_1)\) on a graph \(G\), written \(\mathrm{\mathbf{{cut}}}\left(C_0,C_1\right)\), is the number of edges with an edge in each cluster:
\[
\begin{aligned}
\mathrm{\mathbf{{cut}}}\left(C_0,C_1\right) &\triangleq \sum_{i \in C_0, j \in C_1} a_{ij}
\end{aligned}
\]
The volume of a set \(C\subseteq N\) is the sum of the degrees of the nodes in \(C\):
\[ \begin{aligned} \mathrm{\mathbf{{vol}}}\left(C\right) &\triangleq \sum_{i \in C} k_i = \sum_{i \in C} \sum_{j \in N} a_{ij}\;. \end{aligned} \]
Let’s implement the cut and volume functions in Python given an adjacency matrix \(\mathbf{A}\) and a partition \((C_0, C_1)\) encoded as a vector \(\mathbf{z}\in \left\{0,1\right\}^n\). First, we’ll load some libraries and grab a graph for clustering:
Now we’ll implement the cut and volume.
def cut(A, z):
return np.sum(A[z == 0][:, z == 1])
def vol(A, z, i):
return np.sum(A[z == i])To get a feel for things, let’s see how cut scores look for two clusterings, one of which looks “visually pretty good” and one of which is completely random.
# get a "pretty good" set of clusters using a built-in algorithm.
partition = nx.algorithms.community.louvain.louvain_communities(G, resolution = 0.4)
z = np.array([0 if node in partition[0] else 1 for node in G.nodes()])
# random clusters
z_rand = np.random.randint(0, 2, 34)
# plot the two clusterings side-by-side
pos = nx.spring_layout(G)
fig, ax = plt.subplots(1, 2, figsize = (9, 3.75))
nx.draw(G, pos, ax = ax[0], node_color = z, cmap = plt.cm.BrBG, node_size = 100, vmin = -0.5, vmax = 1.5, edgecolors = 'black')
nx.draw(G, pos, ax = ax[1], node_color = z_rand, cmap = plt.cm.BrBG, node_size = 100, vmin = -0.5, vmax = 1.5, edgecolors = 'black')
t = ax[0].set_title(fr'"Good" clustering: $cut(C_0, C_1)$ = {cut(A, z):.0f}' + "\n" + fr'$vol(C_0)$ = {vol(A, z, 0):.0f}, $vol(C_1)$ = {vol(A, z, 1):.0f}')
t = ax[1].set_title(fr'Random clustering: $cut(C_0, C_1)$ = {cut(A, z_rand):.0f}' + "\n" + fr'$vol(C_0)$ = {vol(A, z_rand, 0):.0f}, $vol(C_1)$ = {vol(A, z_rand, 1):.0f}')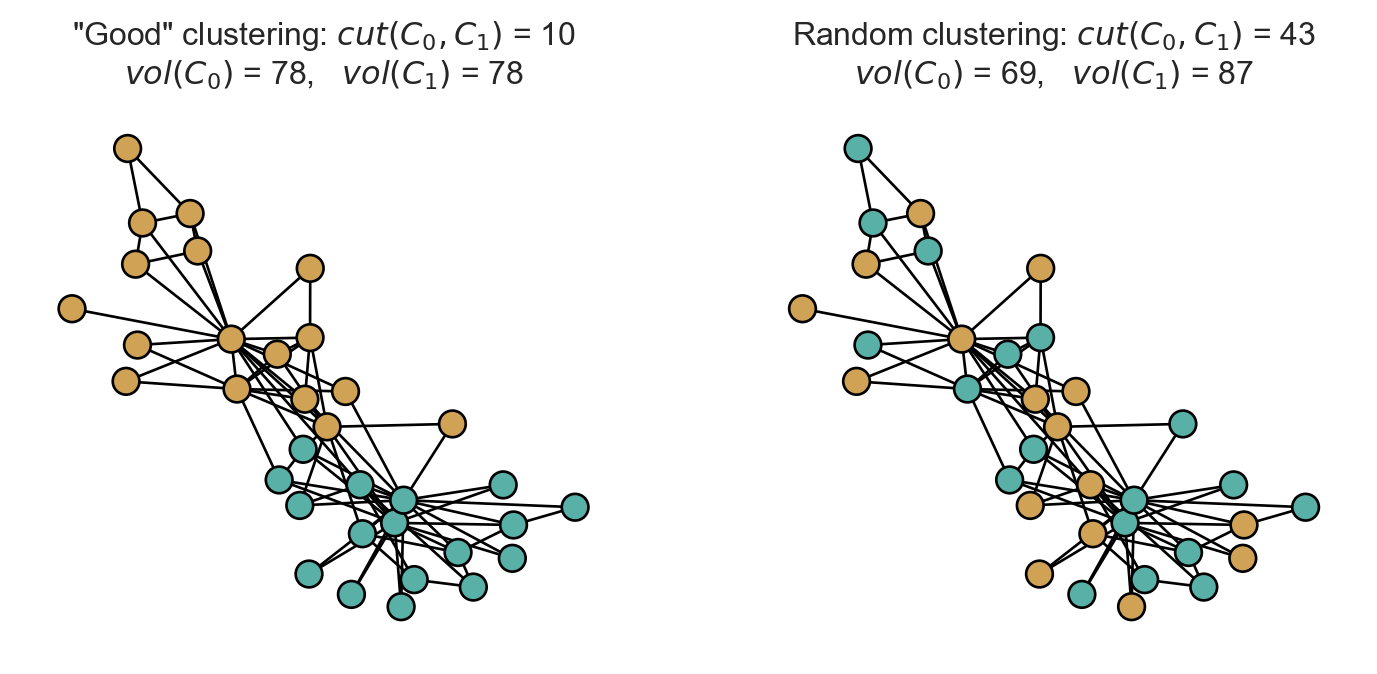
The visually appealing clustering has a substantially lower cut score than the random clustering.
Engineering an Objective Function
How can we use the cut and volume to find useful clusterings? Our general idea is to seek a biclustering \((C_0, C_1)\) that that minimizes some function \(f(C_0, C_1)\) defined in terms of the cut and volume:
\[ \begin{aligned} C_0^*, C_1^* = \mathop{\mathrm{arg\,min}}_{C_0, C_1} f(C_0, C_1)\;. \end{aligned} \]
The function \(f\) should be small when \((C_0, C_1)\) is a “good” clustering and large when \((C_0, C_1)\) is a “bad” clustering. How can we combine the cut and volume in order to express this idea?
One initially appealing idea is to simply let \(f\) be the cut size:
\[ \begin{aligned} f(C_0, C_1) = \mathrm{\mathbf{{cut}}}\left(C_0,C_1\right)\;. \end{aligned} \]
The problem with this approach is that it encourages us to put every node in the same cluster. For example, if \(C_0 = N\) and \(C_1 = \emptyset\), then all nodes have label \(0\) and \(\mathrm{\mathbf{{cut}}}\left(C_0,C_1\right) = 0\). This is the smallest realizable cut size, but isn’t a very useful solution to the clustering problem!
A general intuition that guides many approaches to the clustering problem is:
A good clustering produces a small cut while maintaining relatively large volumes for all clusters.
That is, we want \(f(C_0, C_1)\) to be small when \(\mathrm{\mathbf{{cut}}}\left(C_0,C_1\right)\) is small and \(\mathrm{\mathbf{{vol}}}\left(C_0\right)\) and \(\mathrm{\mathbf{{vol}}}\left(C_1\right)\) are large.
Here’s one candidate \(f\) that encodes this intuition. Let \(\mathrm{\mathbf{{vol}}}\left(G\right) = \sum_{i \in N} k_i = 2m\) be the total volume of the graph. Then, let
\[ \begin{aligned} f(C_0, C_1) = \mathrm{\mathbf{{cut}}}\left(C_0,C_1\right) + \frac{1}{4\mathrm{\mathbf{{vol}}}\left(G\right)}\left(\mathrm{\mathbf{{vol}}}\left(C_0\right) - \mathrm{\mathbf{{vol}}}\left(C_1\right)\right)^2\;. \end{aligned} \]
Observe that this function \(f\) has two counterbalancing terms. The first term is small when the cut term is small, while the second term is small when the two clusters \(C_0\) and \(C_1\) have similar volumes, and vanishes in the case when the two clusters have identical volumes. In fact, this function \(f\) is a disguised form of the modularity, which we have previously seen. As shown by Gleich and Mahoney (2016), minimizing \(f\) is equivalent to maximizing the modularity.
Since we’ve already seen modularity maximization, let’s consider a different way of managing the tradeoff between cut and volume. Consider the objective function
\[ \begin{aligned} f(C_0, C_1) = \mathrm{\mathbf{{cut}}}\left(C_0,C_1\right)\left(\frac{1}{\mathrm{\mathbf{{vol}}}\left(C_0\right)} + \frac{1}{\mathrm{\mathbf{{vol}}}\left(C_1\right)}\right)\;. \end{aligned} \]
This is the normalized cut or NormCut objective function, and its minimization is the problem that will guide our development of spectral clustering.
Let’s implement the normalized cut and check that it gives a lower score to the “good” clustering than to the random clustering:
def norm_cut(A, z):
return cut(A, z)*(1/vol(A, z, 0) + 1/vol(A, z, 1))print(f"NormCut of good clustering: {norm_cut(A, z):.2f}")
print(f"NormCut of random clustering: {norm_cut(A, z_rand):.2f}")NormCut of good clustering: 0.26
NormCut of random clustering: 1.16As expected, the normcut of the good clustering is much lower than the normcut of the random clustering.
From NormCut to Eigenvectors
Is that it? Are we done? Could we simply define a clustering algorithm that finds clusters which minimize the NormCut? Unfortunately, this appealing idea isn’t practical: the problem of finding the partition that minimizes the normalized cut is NP-hard (Wagner and Wagner 1993). So, in order to work with large instances, we need to find an approximate solution of the NormCut minimization problem that admits an efficient solution.
Our strategy is to express the NormCut objective in linear algebraic terms. To do this, define the vector \(\mathbf{y}\in \mathbb{R}^n\) with entries
Recall that the condition \(i \in C_0\) is equivalent to \(z_i = 0\).
\[ \begin{aligned} y_i = \begin{cases} &\frac{1}{\sqrt{2m}}\sqrt{\frac{\mathrm{\mathbf{{vol}}}\left(C_1\right)}{\mathrm{\mathbf{{vol}}}\left(C_0\right)}} & \text{if } i \in C_0\;, \\ -&\frac{1}{\sqrt{2m}}\sqrt{\frac{\mathrm{\mathbf{{vol}}}\left(C_0\right)}{\mathrm{\mathbf{{vol}}}\left(C_1\right)}} & \text{if } i \in C_1\;. \end{cases} \end{aligned} \tag{13.1}\]
The vector \(\mathbf{y}\) is as good as \(\mathbf{z}\) for the purposes of clustering: the sign of \(y_i\) completely determines the cluster of node \(i\).
These properties tell us something important about \(\mathbf{y}\):
- The NormCut objective function can be expressed as a quadratic form in \(\mathbf{y}\); we want to find a choice of \(\mathbf{y}\) that minimizes this objective.
- The vector \(\mathbf{y}\) has a natural scale; it always satisfies \(\mathbf{y}^T\mathbf{D}\mathbf{y}= 1\).
- The vector \(\mathbf{y}\mathbf{D}\) is orthogonal to the all-ones vector \(\mathbb{1}\). This is an expression of the idea that the volumes of the two clusters shouldn’t be too different; we must have \(\sum_{i \in C_0} y_i k_{i} = \sum_{i \in C_1} y_i k_{i}\).
So, the problem of minimizing the NormCut objective is the same as the problem
We’ve ignored the factor of \(2m\) in the objective function since it wouldn’t change our choice of optimal \(\mathbf{y}\).
\[ \begin{aligned} \mathbf{y}^* = \mathop{\mathrm{arg\,min}}_{\mathbf{y}\in \mathcal{Y}} \; \mathbf{y}^T \mathbf{L}\mathbf{y}\quad \text{ subject to } \quad \mathbf{y}^T\mathbf{D}\mathbf{y}= 1 \quad \text{and} \quad \mathbf{y}\mathbf{D}\mathbb{1}= 0\;, \end{aligned} \tag{13.2}\]
where \(\mathcal{Y}\) is the set of all vectors \(\mathbf{y}\) of the form specified by Equation 13.1 for some choice of \(\mathbf{z}\).
Let’s now change our perspective a bit: rather than requiring that \(\mathbf{y}\in \mathcal{Y}\) have the exact form described above, we’ll instead treat \(\mathbf{y}\) as an arbitrary unknown vector in \(\mathbb{R}^n\) and attempt to minimize over this domain instead:
\[ \begin{aligned} \mathbf{y}^* = \mathop{\mathrm{arg\,min}}_{\mathbf{y}\in \mathbb{R}^n} \; \mathbf{y}^T \mathbf{L}\mathbf{y}\quad \text{ subject to } \quad \mathbf{y}^T\mathbf{D}\mathbf{y}= 1 \quad \text{and} \quad \mathbf{y}\mathbf{D}\mathbb{1}= 0\;, \end{aligned} \tag{13.3}\]
This is an approximation to the original problem and the approach is common enough to have a name: Problem 13.3 is the continuous relaxation of Problem 13.2. This relaxed problem is the problem solved by Laplacian spectral clustering.
It is now time to explain the word “spectral” in “Laplacian spectral clustering.” As you may remember, “spectral methods” are methods which rely on the eigenvalues and eigenvectors of matrices. So, our claim is that we are going to solve Problem 13.3 by finding the eigenvector of a certain matrix. Let’s see why.
Let’s make a small change of variables. Define \(\mathbf{x}= \mathbf{D}^{1/2} \mathbf{y}\). Then, we can rewrite the objective function as a function of \(\mathbf{x}\):
\[ \begin{aligned} \mathbf{x}^* = \mathop{\mathrm{arg\,min}}_{\mathbf{x}\in \mathbb{R}^n} \; \mathbf{x}^T \tilde{\mathbf{L}} \mathbf{x}\quad \text{subject to} \quad \lVert \mathbf{x} \rVert = 1\quad \text{and} \quad \mathbf{x}^T \mathbf{D}^{1/2} \mathbb{1}= 0\;, \end{aligned} \tag{13.4}\]
where we have defined \(\tilde{\mathbf{L}} = \mathbf{D}^{-1/2} \mathbf{L}\mathbf{D}^{-1/2}\).
The previous exercise shows that Problem 13.4 involves minimizing the quadratic form \(\mathbf{x}^T \tilde{\mathbf{L}} \mathbf{x}\) subject to the constraint \(\lVert \mathbf{x} \rVert = 1\) and the requirement that \(\mathbf{x}\) be orthogonal to the smallest eigenvalue of \(\tilde{\mathbf{L}}\). We proved on a homework assignment a while back that the solution to this problem is the eigenvector \(\mathbf{x}^*\) corresponding to the second-smallest eigenvalue \(\lambda_2\) of \(\tilde{\mathbf{L}}\).
A more general version of this result is called the Courant-Fischer-Weyl theorem.
Remember that \(\mathbf{x}^*\) wasn’t actually the vector we wanted; we were looking for \(\mathbf{y}^* = \mathbf{D}^{-1/2} \mathbf{x}^*\). What can we say about \(\mathbf{y}^*\)? Consider the eigenvalue relation for \(\mathbf{x}^*\):
\[ \begin{aligned} \tilde{\mathbf{L}} \mathbf{x}^* = \lambda_2 \mathbf{x}^*\;. \end{aligned} \]
Let’s replace \(\mathbf{x}^*\) with \(\mathbf{D}^{1/2} \mathbf{y}^*\):
\[ \begin{aligned} \tilde{\mathbf{L}} \mathbf{D}^{1/2} \mathbf{y}^* = \lambda_2 \mathbf{D}^{1/2} \mathbf{y}^*\;. \end{aligned} \]
Finally, let’s multiply on both sides by \(\mathbf{D}^{-1/2}\):
\[ \begin{aligned} \mathbf{D}^{-1/2} \tilde{\mathbf{L}} \mathbf{D}^{1/2} \mathbf{y}^* = \lambda_2 \mathbf{y}^*\;. \end{aligned} \]
The lefthand side simplifies, since \(\tilde{\mathbf{L}} = \mathbf{D}^{-1/2} \mathbf{L}\mathbf{D}^{-1/2}\):
\[ \begin{aligned} \lambda_2 \mathbf{y}^* = \mathbf{D}^{-1/2} \tilde{\mathbf{L}} \mathbf{D}^{1/2} \mathbf{y}^* = \mathbf{D}^{-1}\mathbf{L}\mathbf{y}^*\;. \end{aligned} \]
That is, the optimal vector \(\mathbf{y}^*\) is an eigenvector of the matrix \(\hat{\mathbf{L}} = \mathbf{D}^{-1}\mathbf{L}\) with eigenvalue \(\lambda_2\). The matrix \(\hat{\mathbf{L}}\) is sometimes called the random-walk Laplacian and indeed has applications in the study of random walks on graphs.
The signs of the entries of \(\mathbf{y}\) then give us a guide to the clusters in which we should place nodes.
The Spectral Biclustering Algorithm
We have come a long way to derive a relatively simple algorithm. Spectral clustering says that, to find a good clustering of a (connected) graph, we should:
- Form the matrix \(\hat{\mathbf{L}} = D^{-1}(D - \mathbf{A})\).
- Compute the eigenvector \(\mathbf{y}_2\) corresponding to the second-smallest eigenvalue \(\lambda_2\).
- Assign node \(i\) to cluster \(0\) if \(y_i < 0\) and cluster \(1\) if \(y_i \geq 0\).
Let’s go ahead and implement this algorithm. The centerpiece of our implementation is a function that accepts a graph \(G\) and returns the eigenvector \(\mathbf{y}_2\). This eigenvector is often called the Fielder eigenvector of the graph after Miroslav Fiedler, who pioneered the idea that the eigenvalues of the Laplacian could be used to study the connectivity structure of graphs.
def fiedler_eigenvector(G):
A = nx.to_numpy_array(G)
D = np.diag(np.sum(A, axis = 1))
L = D - A
L_hat = np.linalg.inv(D) @ L
eigvals, eigvecs = np.linalg.eig(L_hat)
return eigvecs[:, 1]Let’s try computing the Fiedler eigenvector on the karate club graph:
fiedler = fiedler_eigenvector(G)And now let’s visualize it!
fig, ax = plt.subplots(1, 1, figsize = (4.5, 3.75))
nx.draw(G, pos, ax = ax, node_color = fiedler, cmap = plt.cm.BrBG, node_size = 100, edgecolors = 'black', vmin = -0.2, vmax = 0.2)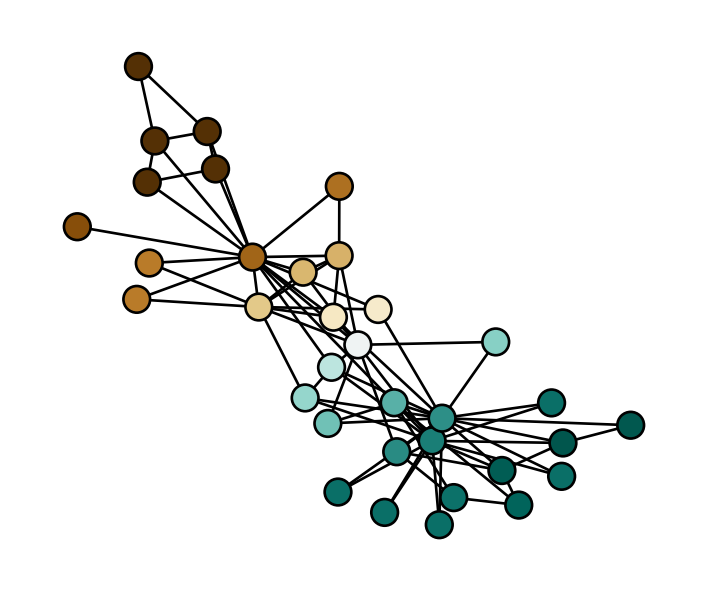
We can think of the Fiedler eigenvector as returning a “soft” clustering that gives each node a score rather than a fixed label. We can obtain labels by thresholding according to sign:
z_fiedler = 1*(fiedler > 0)
fig, ax = plt.subplots(1, 1, figsize = (4.5, 4))
nx.draw(G, pos, ax = ax, node_color = z_fiedler, cmap = plt.cm.BrBG, node_size = 100, edgecolors = 'black', vmin = -0.5, vmax = 1.5)
t = ax.set_title(fr'Laplacian clustering: $cut(C_0, C_1)$ = {cut(A, z_fiedler):.0f}' + "\n" + fr'$vol(C_0)$ = {vol(A, z_fiedler, 0):.0f}, $vol(C_1)$ = {vol(A, z_fiedler, 1):.0f}')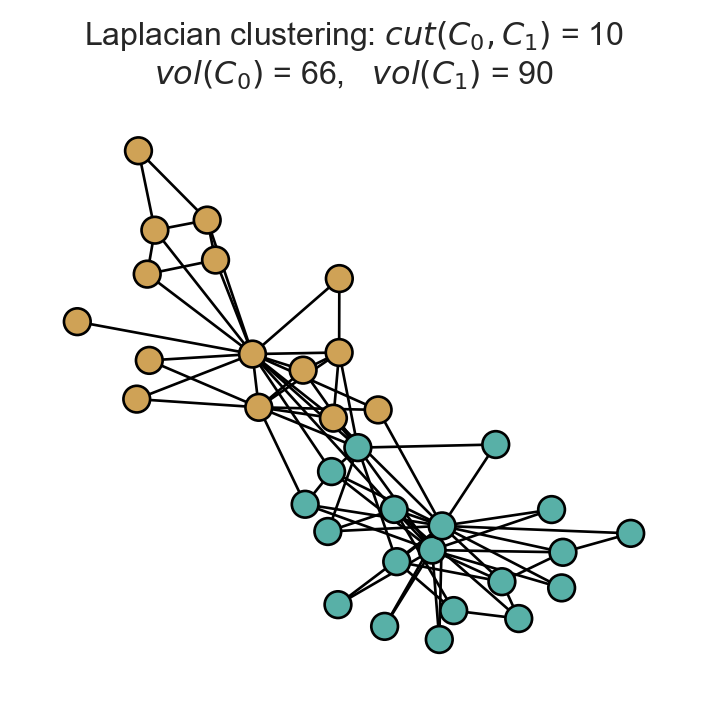
This clustering looks pretty reasonable! Since we are only approximately solving the NormCut problem, it is not strictly guaranteed that this clustering is the best possible one in any sense.
Multiway Spectral Clustering
It is also possible to use spectral clustering to split a graph into more than two pieces. The general idea is that, when \(k\) clusters are desired, we should compute the eigenvectors corresponding to the \(k\) smallest eigenvalues of the matrix \(\hat{\mathbf{L}}\) and collect them in a matrix
\[ \begin{aligned} \mathbf{Y}= \begin{bmatrix} \mathbf{y}_1 & \mathbf{y}_2 & \cdots & \mathbf{y}_k \end{bmatrix}\;. \end{aligned} \]
The row \(\mathbf{y}_i = [v_{i1}, v_{i2}, \ldots, v_{ik}]\) of \(\mathbf{Y}\) can be thought of as a set of spatial (Euclidean) coordinates for node \(i\). We can then use a Euclidean clustering algorithm like \(k\)-means in the space of these coordinates in order to obtain a final clustering.
from sklearn.cluster import KMeans
def multiway_spectral(G, k):
# same as before
A = nx.to_numpy_array(G)
D = np.diag(np.sum(A, axis = 1))
L = D - A
L_hat = np.linalg.inv(D) @ L
eigvals, eigvecs = np.linalg.eig(L_hat)
# Now we get the eigenvectors from the second to the k-th smallest
idx = np.argsort(eigvals)
Y = eigvecs[:, idx[0:k]]
# cluster in the Euclidean space
KM = KMeans(n_clusters = k)
KM.fit(Y)
return KM.labels_Let’s try this on the Les Mis graph!
G = unweight(nx.les_miserables_graph())
labels = multiway_spectral(G, 5)
fig, ax = plt.subplots(1, 1, figsize = (6, 5))
nx.draw(G, ax = ax, cmap = plt.cm.Set3, node_color = labels, node_size = 100, edgecolors = 'black')
Visually, the results look fairly reasonable. Multiway spectral clustering can also be justified in terms of approximate normalized cut minimization; see Luxburg (2007) for details.
References
Gleich, David F, and Michael W Mahoney. 2016. “Mining Large Graphs.” In Handbook of Big Data.
Luxburg, Ulrike von. 2007. “A Tutorial on Spectral Clustering.” arXiv. https://arxiv.org/abs/0711.0189.
Shi, Jianbo, and Jitendra Malik. 2000. “Normalized Cuts and Image Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 22 (8): 888–905.
Wagner, Dorothea, and Frank Wagner. 1993. “Between Min Cut and Graph Bisection.” In Mathematical Foundations of Computer Science 1993: 18th International Symposium, MFCS’93 Gdańsk, Poland, August 30–September 3, 1993 Proceedings 18, 744–50. Springer.
© Heather Zinn Brooks and Phil Chodrow, 2025